MindPower: Enabling Theory-of-Mind Reasoning in VLM-based Embodied Agents
Jian-Yu Jiang-Lin2 Bin Wen1 Hongxia Xie1 Jianlong Fu3 Wen-Huang Cheng2
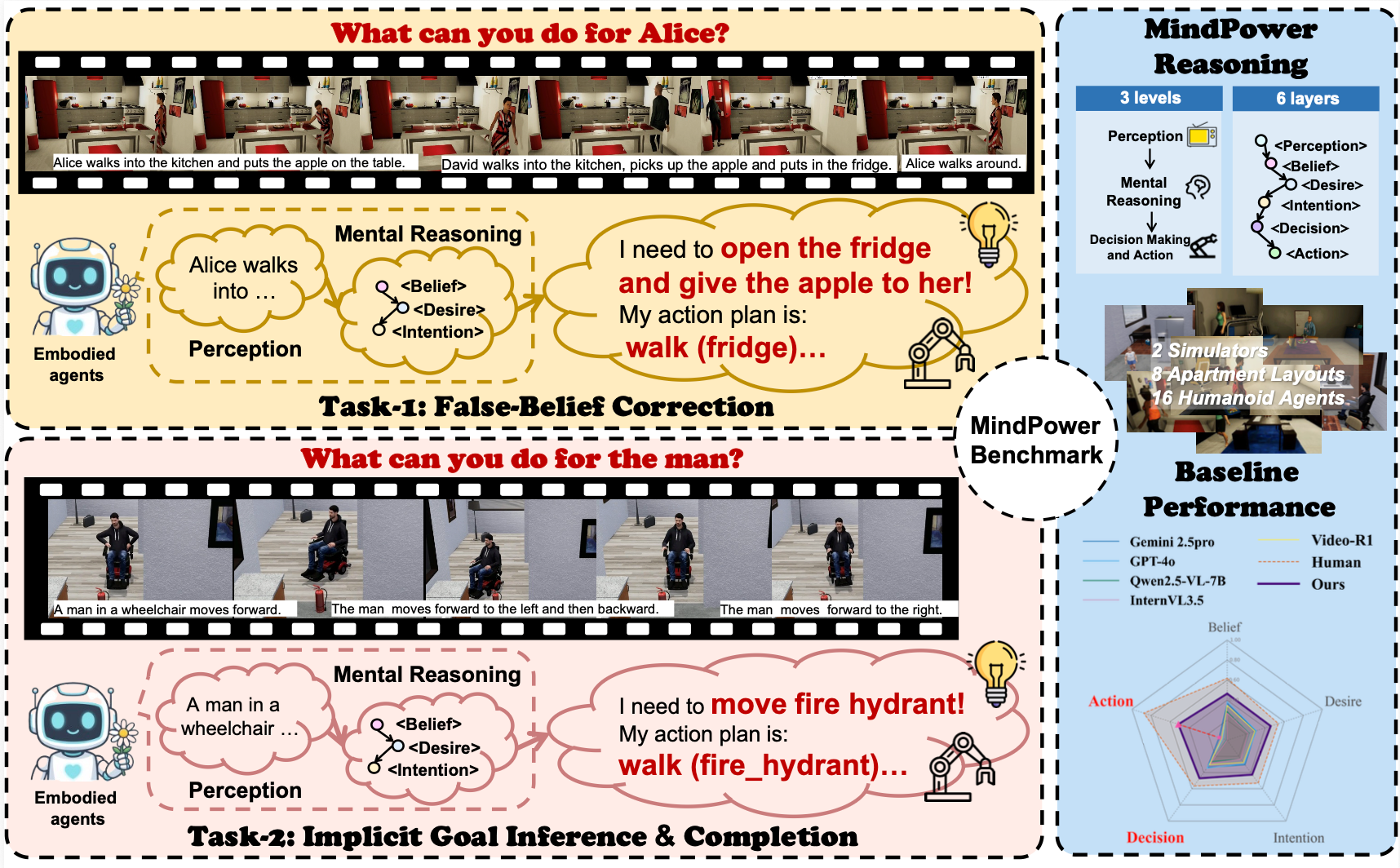
Figure 1: MindPower Benchmark Overview. We evaluate Robot-Centric ToM through two tasks: False-Belief Correction and Implicit Goal Inference & Completion, assessing whether VLM-based embodied agents can generate correct decisions and actions. We further propose the MindPower Reasoning Hierarchy, comprising three levels and six layers. Existing VLMs perform poorly across layers, especially in action reasoning, while our model shows substantial improvements.
Abstract
Theory of Mind (ToM) refers to the ability to infer others’ mental states, such as beliefs, desires, and intentions. Current vision–language embodied agents lack ToM-based decision-making, and existing benchmarks focus solely on human mental states while ignoring the agent’s own perspective, hindering coherent decision and action generation. To address this, we propose MindPower, a Robot-Centric framework integrating Perception, Mental Reasoning, Decision Making and Action. Given multimodal inputs, MindPower first perceives the environment and human states, then performs ToM Reasoning to model both self and others, and finally generates decisions and actions guided by inferred mental states. Furthermore, we introduce Mind-Reward, a novel optimization objective that encourages VLMs to produce consistent ToM Reasoning and behavior. Our model outperforms GPT-4o by 12.77% in decision making and 12.49% in action generation.
ToM-Embodied Benchmark

Figure 2: MindPower Reasoning Hierarchy. The agent first receives multimodal input, then performs mental reasoning to form beliefs, desires, and intentions, and finally makes decisions and generate action plan based on this reasoning.
Evaluation Tasks
False-Belief Correction
Evaluate whether an embodied agent can detect and correct a human’s mistaken belief about the environment (e.g., misjudged object locations).
Implicit Goal Inference
Test the agent’s ability to infer unstated intentions from subtle behavioral cues, such as searching or repeated failed attempts.
MindPower Reasoning Hierarchy
Perception
Mental Reasoning
Decision & Action
Method

Framework Overview
To effectively train the agent, we employ a two-stage pipeline:
- Stage 1: Supervised Fine-Tuning (SFT) establishs fundamental capabilities.
- Stage 2: Group Relative Policy Optimization (GRPO) combines Mind-Reward and Format-Reward, to enhance BDI consistency and Robot-Centric optimality.
Experimental Results
Table 1: Quantitative Evaluation. We evaluate our model against both image-based and video-based VLMs. “B” denotes the BERTScore, “S” represents the Sentence Transformer score, and “BPC” means BDI and Perspective Consistency. The BPC score ranges from 0 to 10, while all other metrics are normalized to a range of 0 to 100.
| Method | Perception | Belief | Desire | Intention | Decision | Action | BPC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | S | B | S | B | S | B | S | B | S | SR | AC | ||
| Human Study | |||||||||||||
| Human Baseline | - | - | 47.65 | 61.81 | 46.76 | 53.71 | 39.18 | 52.93 | 34.55 | 56.66 | 19.37 | 26.26 | 8.19 |
| Video-input | |||||||||||||
| Gemini-2.5 Flash | 31.10 | 48.36 | 29.07 | 38.64 | 28.36 | 30.69 | 19.05 | 29.04 | 21.68 | 34.57 | 1.38 | 1.35 | 8.72 |
| Gemini-2.5 Pro | 24.62 | 43.43 | 32.02 | 36.79 | 31.38 | 30.21 | 22.65 | 30.33 | 24.23 | 33.87 | 2.08 | 2.54 | 8.56 |
| Qwen2.5-VL-7B-Instruct | 26.05 | 38.20 | 20.27 | 28.43 | 26.05 | 22.93 | 16.01 | 23.21 | 16.69 | 26.56 | 0.29 | 0.22 | 6.07 |
| VideoLLaMA3-7B | 14.80 | 31.86 | 7.82 | 30.08 | 8.09 | 21.76 | 4.61 | 24.28 | 5.34 | 19.59 | 0.63 | 0.60 | 5.33 |
| InternVL3.5-8B | 23.23 | 42.26 | 21.98 | 26.90 | 22.20 | 22.45 | 16.53 | 23.21 | 15.64 | 28.76 | 0.10 | 0.08 | 6.52 |
| Video-LLaVA | 2.96 | 25.33 | 5.05 | 14.87 | 6.82 | 15.55 | 16.63 | 15.30 | 3.29 | 19.50 | 0.08 | 0.08 | 4.81 |
| Video-ChatGPT | 7.04 | 27.00 | 9.90 | 25.72 | 5.16 | 16.79 | 2.70 | 21.44 | 1.46 | 19.95 | 0.00 | 0.00 | 5.52 |
| VideoChat-R1 | 27.47 | 42.47 | 21.57 | 30.11 | 22.56 | 20.36 | 15.03 | 24.70 | 17.21 | 25.71 | 0.64 | 0.82 | 6.00 |
| Video-R1 | 30.56 | 47.46 | 25.56 | 34.58 | 26.68 | 29.17 | 17.13 | 27.56 | 18.91 | 30.33 | 1.43 | 1.72 | 6.45 |
| Image-input | |||||||||||||
| GPT-4o | 33.07 | 48.37 | 30.05 | 39.47 | 31.16 | 32.75 | 16.16 | 29.55 | 19.96 | 34.35 | 1.82 | 2.91 | 8.05 |
| Qwen2.5-VL-7B-Instruct | 24.89 | 39.97 | 19.46 | 29.21 | 22.59 | 19.14 | 16.80 | 23.49 | 19.11 | 23.79 | 0.15 | 0.15 | 6.72 |
| InternVL3.5-8B | 6.43 | 18.78 | 15.71 | 20.77 | 19.30 | 17.38 | 13.97 | 19.72 | 12.62 | 18.77 | 0.00 | 0.00 | 5.95 |
| LLaVA-OV-8B | 8.08 | 26.45 | 15.09 | 23.21 | 22.31 | 21.40 | 16.21 | 19.58 | 17.11 | 21.25 | 0.00 | 0.00 | 6.45 |
| Ours | |||||||||||||
| Mind-Reward only | 21.84 | 39.99 | 18.70 | 27.81 | 21.35 | 18.85 | 21.90 | 23.30 | 17.58 | 24.68 | 0.28 | 0.40 | 6.63 |
| SFT only | 32.78 | 52.72 | 43.15 | 42.48 | 47.01 | 37.83 | 34.86 | 39.48 | 36.70 | 43.84 | 8.50 | 10.48 | 8.78 |
| Ours (SFT+Mind-Reward) | 44.79 | 59.93 | 49.14 | 46.49 | 51.25 | 45.75 | 37.79 | 42.57 | 40.17 | 47.12 | 11.75 | 15.40 | 8.87 |
BibTeX
@article{zhang2025
mindpower,
title={MindPower: Enabling Theory-of-Mind Reasoning in VLM-based Embodied Agents},
author={Zhang, Ruoxuan and Zheng, Qiyun and Zhou, Zhiyu and Liao, Ziqi and Wu, Siyu and Jiang-Lin, Jian-Yu and Wen, Bin and Xie, Hongxia and Fu, Jianlong and Cheng, Wen-Huang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}